


Reverse-engineering et problèmes juridiques autour de l'appli Crush
Je me suis intéressé à la cybersécurité de **Crush**, l'appli de rencont...
Je suis à Stockholm cette semaine pour la conférence @JFokus, et j’ai décidé de participer au quiz de l’un des sponsors. Je crois que j’ai gagné 😇
Voici un petit writeup de cybersécurité dans lequel je vous explique comment j’ai fait.
En voyant que le classement est basé sur la rapidité, j’ai eu envie de l’automatiser pour avoir un temps surhumain.
Mais ça, c’était avant de découvrir trois failles dans l’appli ! (restez jusqu’au bout de l’article, j’ai une technique de hacking ultra puissante à vous montrer)
Avant toute chose, on doit commencer par une phase de reconnaissance : comprendre le fonctionnement du site, sa surface d’attaque, les technos utilisées côté serveur, etc.
Ici très simple, je regarde simplement les requêtes envoyées par mon ordi en faisant le quiz normalement.
Pour ça j’utilise la console Chrome, et sur des attaques plus complexes on peut utiliser l’intercepteur de paquets Burp Suite.
Mon navigateur communique avec le serveur via trois URL différentes (/user, /questions, /highscore) aussi appelées endpoints.
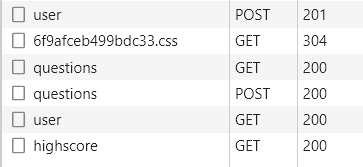
L’endpoint /user sert à créer un nouveau compte, et /highscore nous renvoie le classement des meilleurs joueurs.
Mais celui qui va nous intéresser, c’est /questions.
La liste des questions est tirée aléatoirement parmi un pool d’une vingtaine de QCM, l’endpoint /questions nous renvoie un objet JSON avec la liste des 10 questions à chaque nouvelle partie.
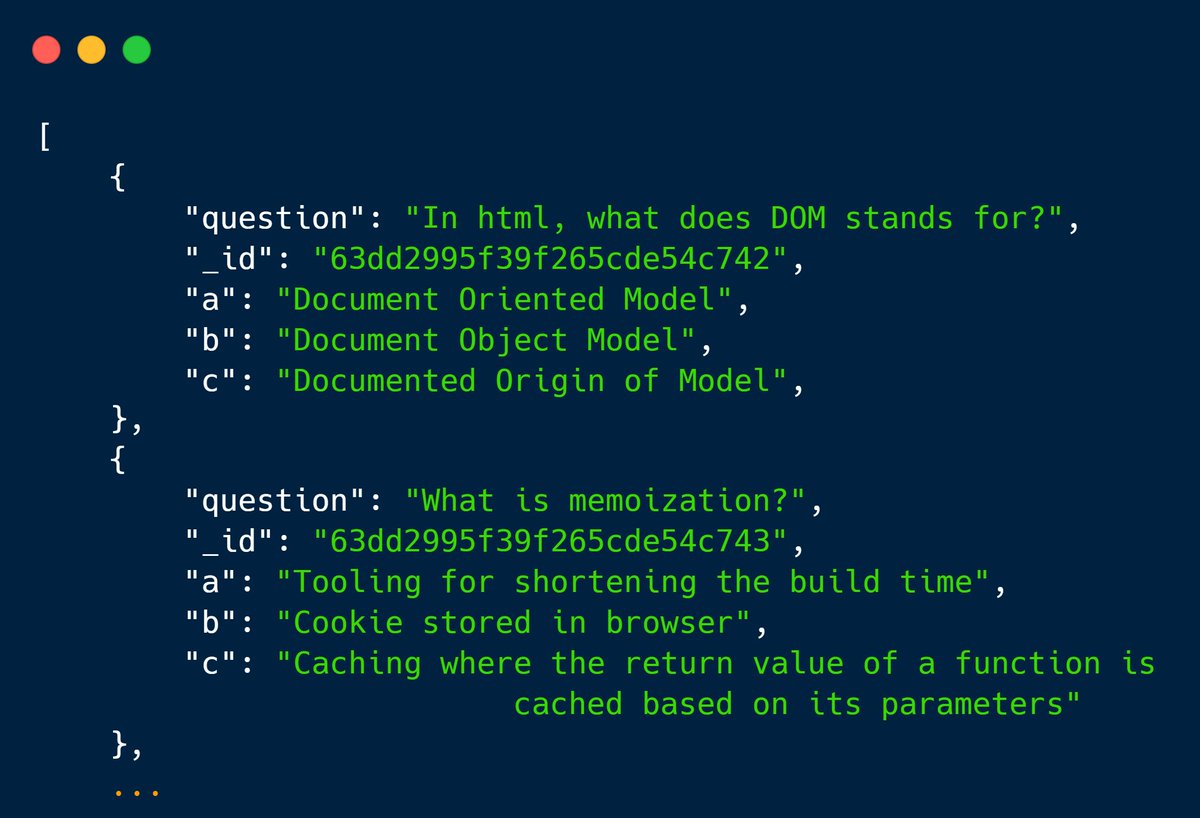
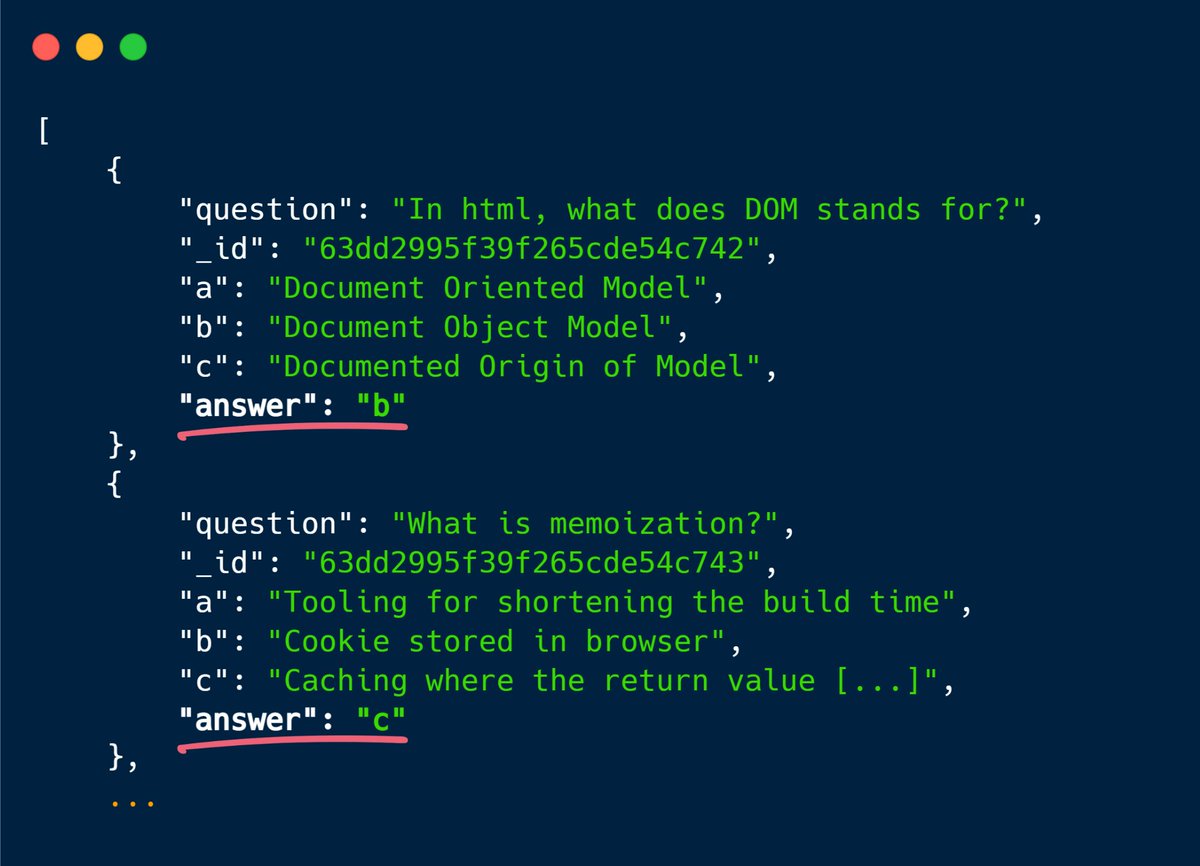
Quand le quiz est terminé, la page renvoie automatiquement ce même JSON au serveur, en y ajoutant un champ contenant la réponse que j’ai donnée pour chaque question :
Pour tricher, on va donc devoir écrire une fonction en Python qui calcule très rapidement les bonnes réponses et les renvoie au serveur pour battre le meilleur score :
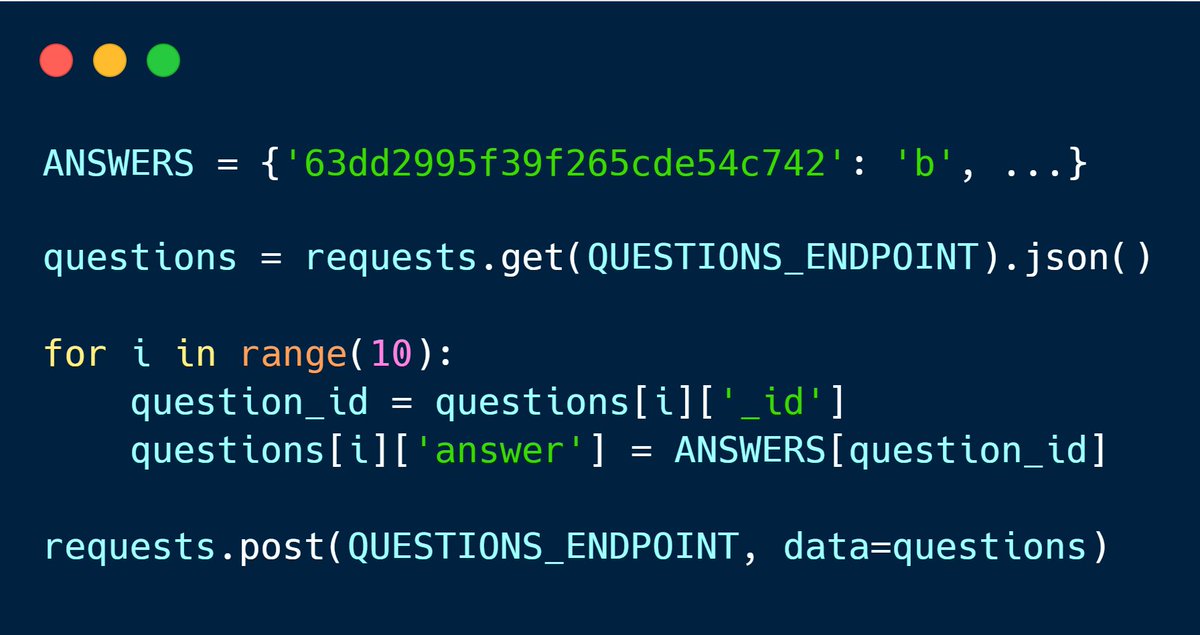
Avec cette technique, on obtient effectivement 10/10 en moins d’une seconde, ce qui est largement suffisant pour se placer en haut du scoreboard.
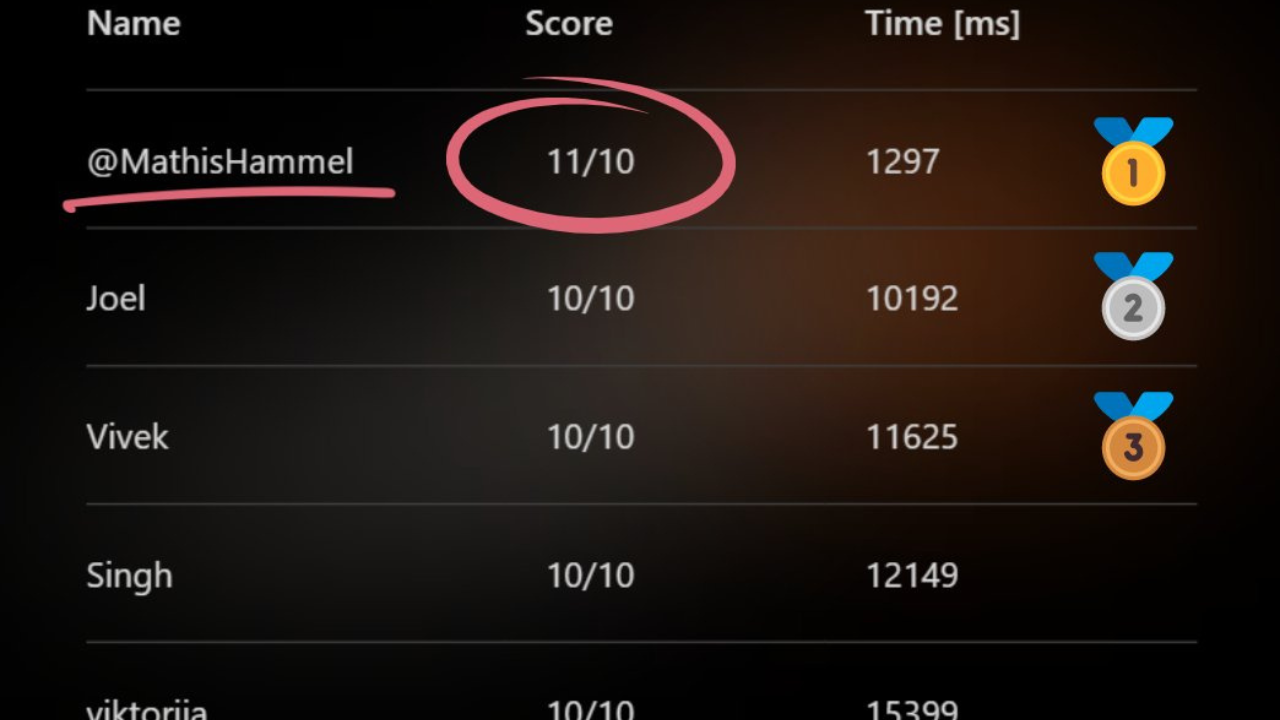
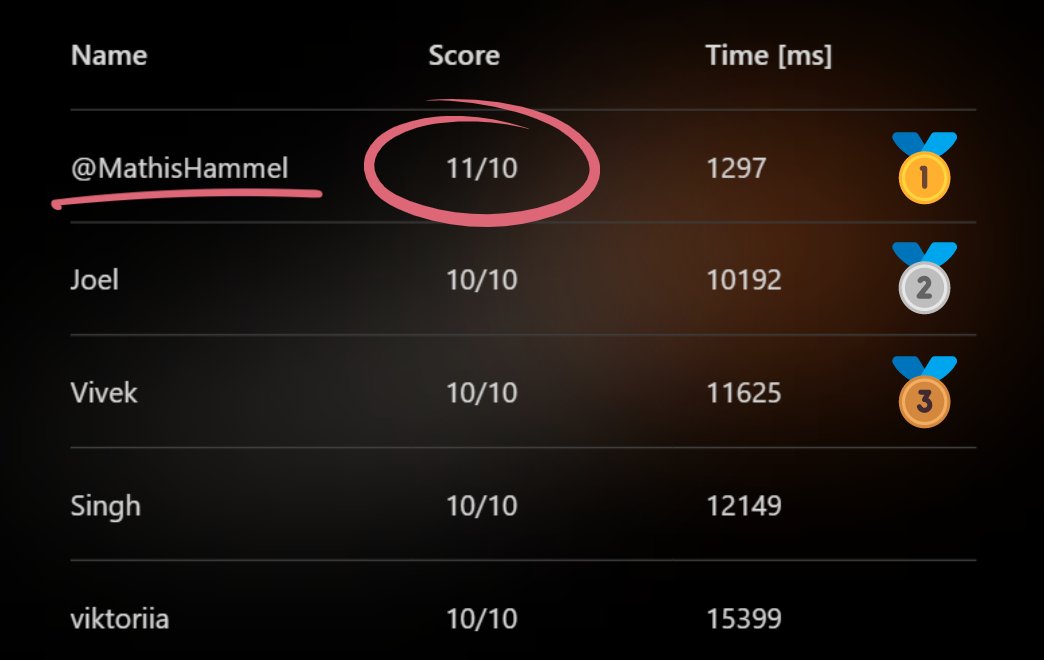
Mais je vous ai promis un 11/10, alors on va creuser un peu plus.
Comment peut-on attaquer l’algorithme de validation pour dépasser le score maximum ?
Comme on n’a pas le code source du serveur, on est face à une boîte noire et il faut essayer de deviner les potentielles erreurs commises au moment du développement de l’app.
Si vous m’avez déjà vu coder en stream, vous savez que les bugs ça me connaît 😏
Mon premier test est de renvoyer une liste incomplète de réponses, pour voir si la vérification accepte des requêtes invalides.
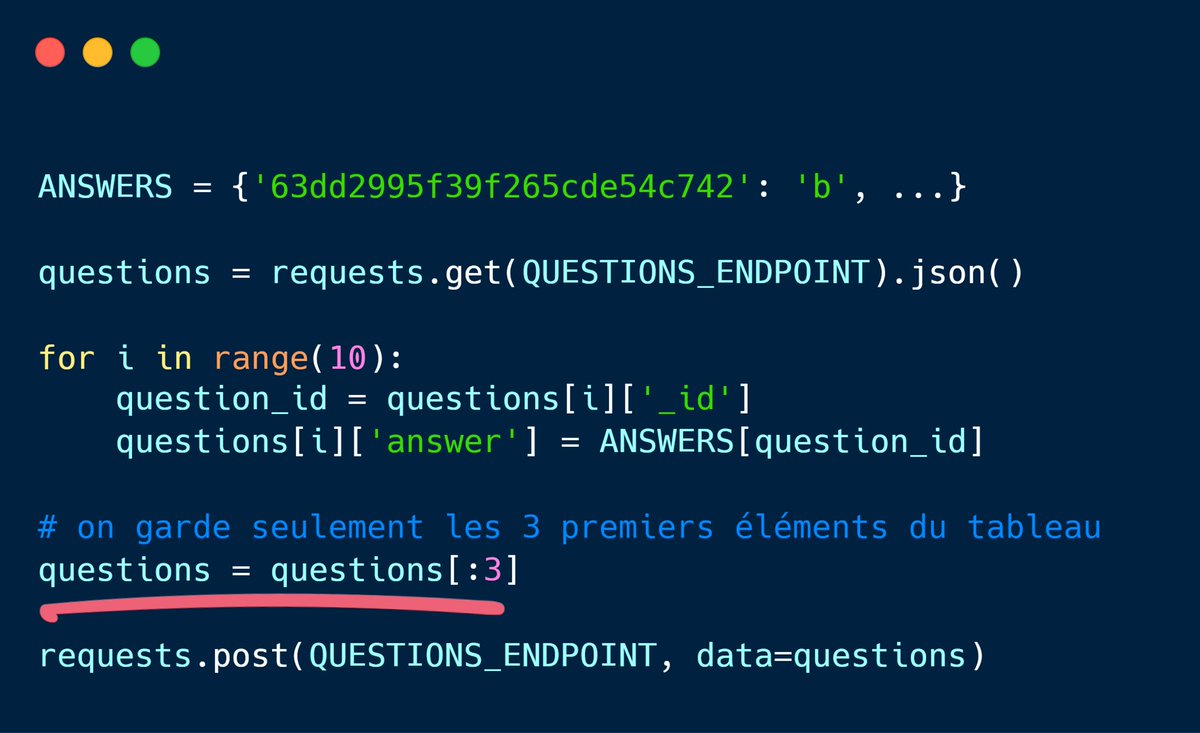
Et ça marche ! En renvoyant seulement 3 réponses, j’ai un score de 3/10.
J’ai rarement été aussi content de ne pas avoir la moyenne, parce qu’à ce moment-là je sais qu’on va pouvoir s’amuser 😈
Maintenant, on a deux options principales à explorer :
Et les deux techniques fonctionnent !
Pour valider un score de 11/10, on va donc utiliser ces deux bugs de validation.
Mon code envoie au serveur 11 fois la bonne réponse sur l’une des questions du pool, et le serveur pense que j’ai répondu 100% correct à un quiz contenant 11 fois la même question !
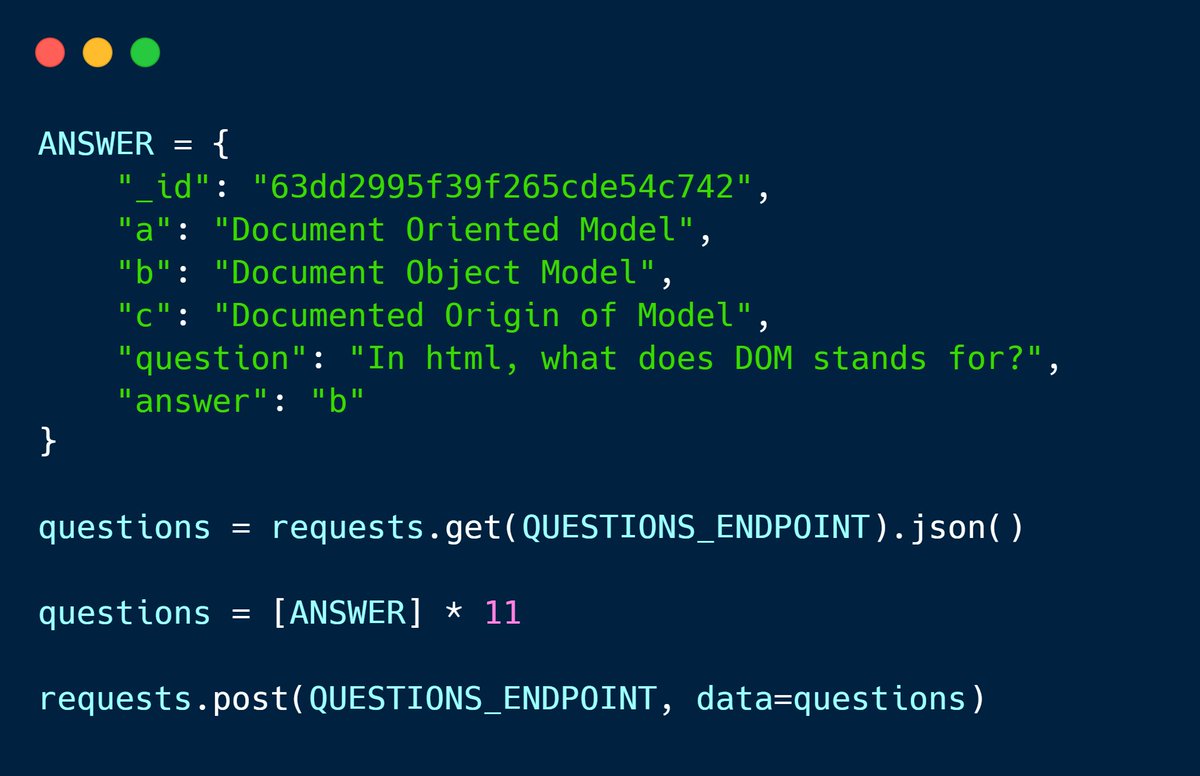
En voyant que c’était aussi facile de tricher (faut pas leur en vouloir, on est pas non plus sur un projet qui garde les codes de la bombe nucléaire), j’ai voulu aller un cran plus loin en contournant la validation des pseudos parce que je tenais à mettre un @ au début du mien.
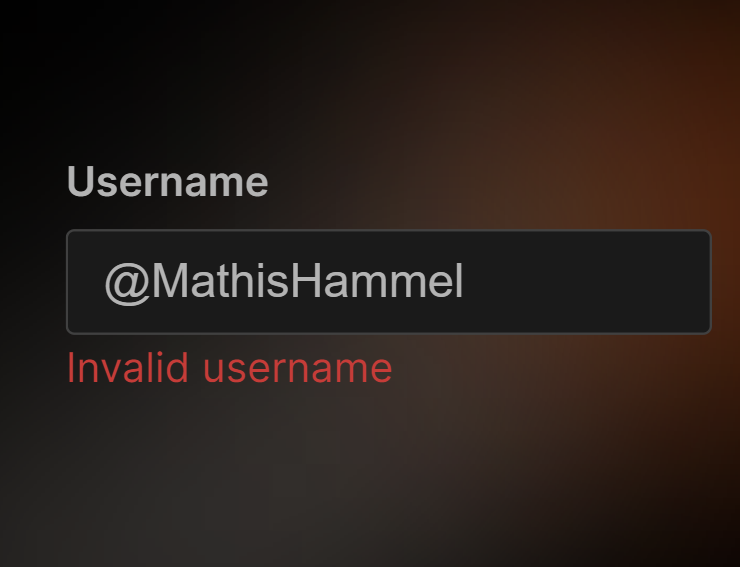
Normalement on ne fait jamais confiance aux données qui proviennent du côté client, mais c’est super courant que les devs oublient la vérification côté serveur.
Du coup, je crafte manuellement la requête qui enregistre n’importe quel nom d’utilisateur, et ça passe 😇
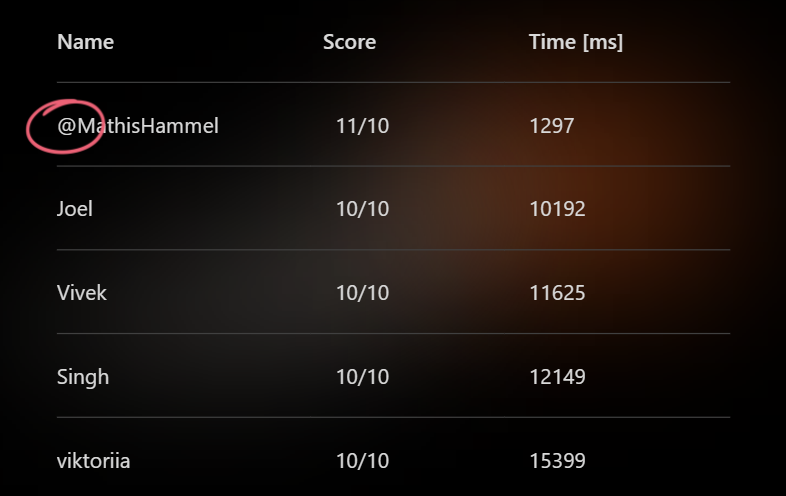
Voilà donc mon mini writeup sur ce quiz qui m’aura probablement beaucoup plus occupé que les autres participants !
Vous voyez qu’avec des outils très simples, on peut trouver des trucs de fou (et je vous assure que ce genre de failles, y’en a absolument partout).
Avant de vous montrer la super technique promise en début d’article, un petit rappel de rigueur : chercher des failles c’est marrant, mais c’est surtout très illégal si vous n’avez pas la permission en amont. Sortez couverts !
Vous l’avez sûrement remarqué, je me sers du langage Python absolument partout, et notamment en compétitions de cybersécurité (Capture The Flag) parce que c’est un langage ultra polyvalent. Laissez-moi vous montrer comment automatiser des requêtes web super facilement.

Les requêtes HTTP/HTTPS en Python se font via le module requests, qui est très simple d’utilisation comme vous avez pu le voir sur les captures d’écran de cet article.
Mais je trouve toujours ça laborieux de simuler un vrai navigateur.
Pour automatiser les actions d’un utilisateur, on doit transmettre au serveur plusieurs infos, notamment via des headers et des cookies de connexion, ce qui est assez fatigant à mettre en place avec du code Python.
Il existe une super technique pour importer dans plein de langages une requête faite par votre navigateur, pour ensuite l’automatiser.
Tout d’abord, dans l’onglet Réseau de la console Chrome/Firefox, clic droit sur la requête qui vous intéresse puis “Copy > Copy as cURL (bash)”
Cette action va mettre dans votre presse-papiers une commande Bash qui reproduit cette requête de manière absolument identique.
Mais comme on n’est pas des sauvages du Bash ici, on a une deuxième étape pour passer ça dans Python.
Certes, ça irait sûrement beaucoup plus vite de faire un os.system pour appeler du Bash directement, mais on a un outil qui propose une manière beaucoup plus élégante : sur http://curlconverter.com vous pouvez transformer la commande cURL vers plein de langages en un clin d’oeil !
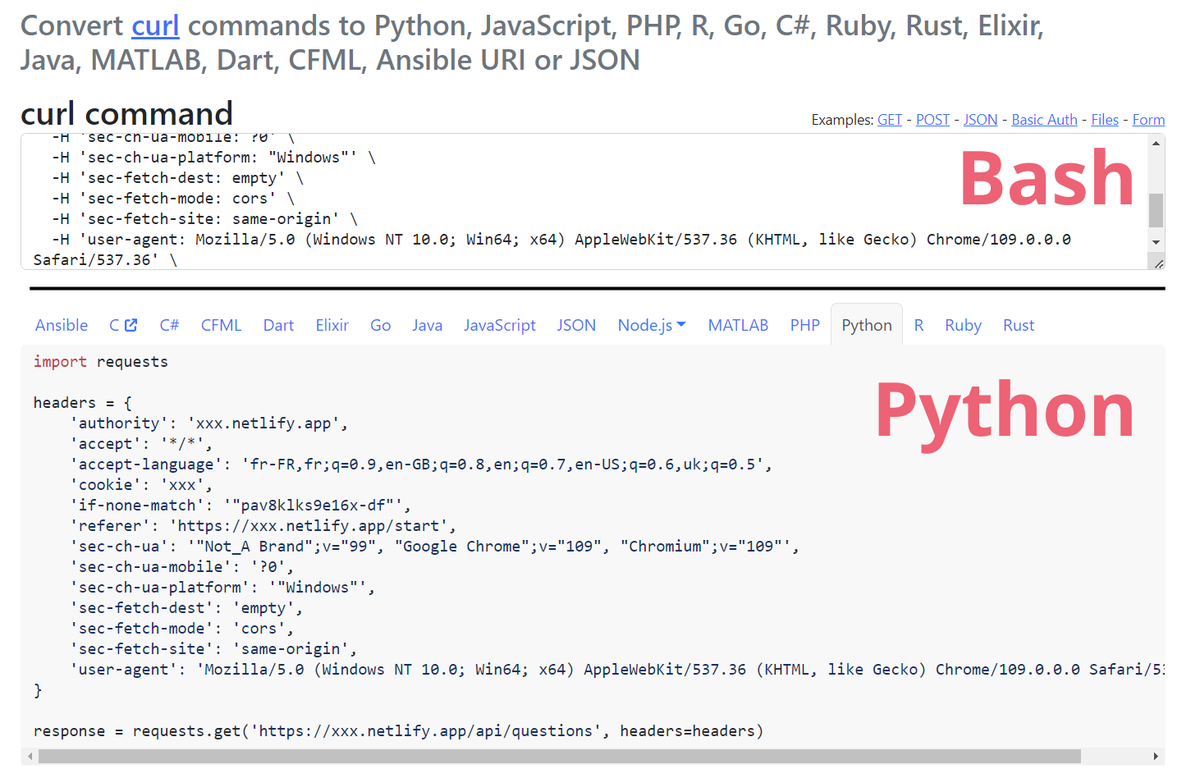
C’est une astuce que j’utilise quasi quotidiennement, très souvent pour automatiser des actions simples, mais aussi parfois pour trouver et exploiter des vulnérabilités sur un serveur web 😇
Merci d’avoir suivi cet article improvisé, et surtout retenez bien : on ne fait jamais confiance à l’utilisateur 😁
Je me suis intéressé à la cybersécurité de **Crush**, l'appli de rencont...
La vulnérabilité que j'ai trouvée dans **Droite au Coeur**, site de renc...
Bon, j'ai trouvé une manière de cracker le nouveau shadowban Twitter 🥳 ...
contact@mathishammel.com
Copier
contact@mathishammel.com
{kind=link}