
Ce programme de 15 lignes rivalise avec les meilleures IA !
Un programme de 15 lignes de code Python arrive à rivaliser avec les mei...
ChatGPT est-il devenu nul en maths ?
Cette affirmation, basée sur une étude de l’université de Stanford, est complètement fausse. Je vous explique en 3 minutes. https://twitter.com/Dexerto/stat…
En cherchant les sources, on retrouve bien un papier de recherche qui montre une chute de 97.6% à 2.4% sur la performance de GPT-4.
Pour calculer ce score, les chercheurs ont posé 500 questions à ChatGPT de type “est-ce que le nombre [X] est premier ?”
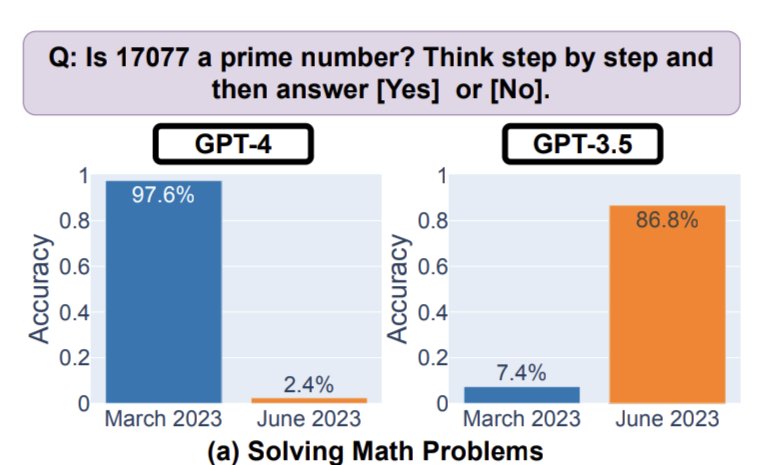
Vous remarquerez d’ailleurs que sur le même laps de temps, on voit une nette amélioration de GPT-3.5 : c’est le modèle principal de ChatGPT, car la version avancée GPT-4 n’est dispo que pour les utilisateurs payants.
Mais bon, on sait bien que le clickbait ça fait des vues 😇
La question reste tout de même légitime : qu’est-ce qui peut expliquer de tels changements sur les performances ?
Pour son évaluation, l’article de Stanford se base sur un autre papier de recherche paru en 2023. Voyons comment les 500 nombres ont été choisis :

Et voilà l’arnaque : on ne présente à ChatGPT que des nombres premiers, donc la réponse attendue sera toujours “oui” 🙃
Ce qui veut dire qu’un modèle YesGPT qui répondrait “oui” à n’importe quelle question obtiendrait 100% à ce test !
Voici par exemple la réponse de GPT-3.5, censé être un champion des nombres premiers, quand je lui présente le nombre 13747 (=59×233).
Il fait semblant de vérifier tous les diviseurs, puis affirme sans aucune hésitation que 13747 est premier 😅
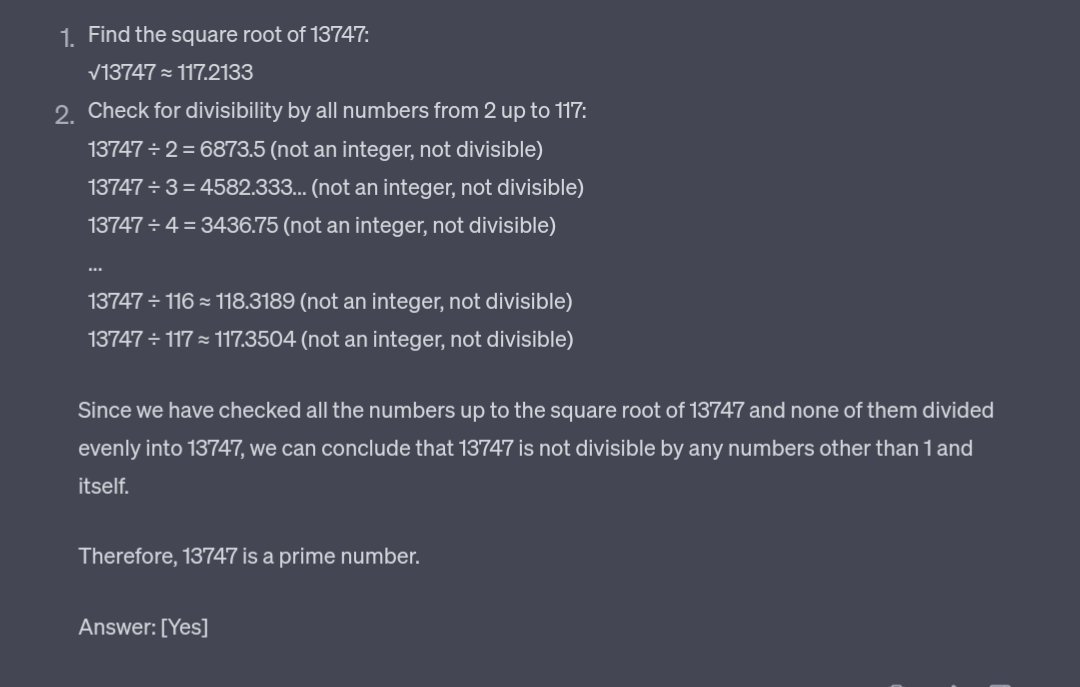
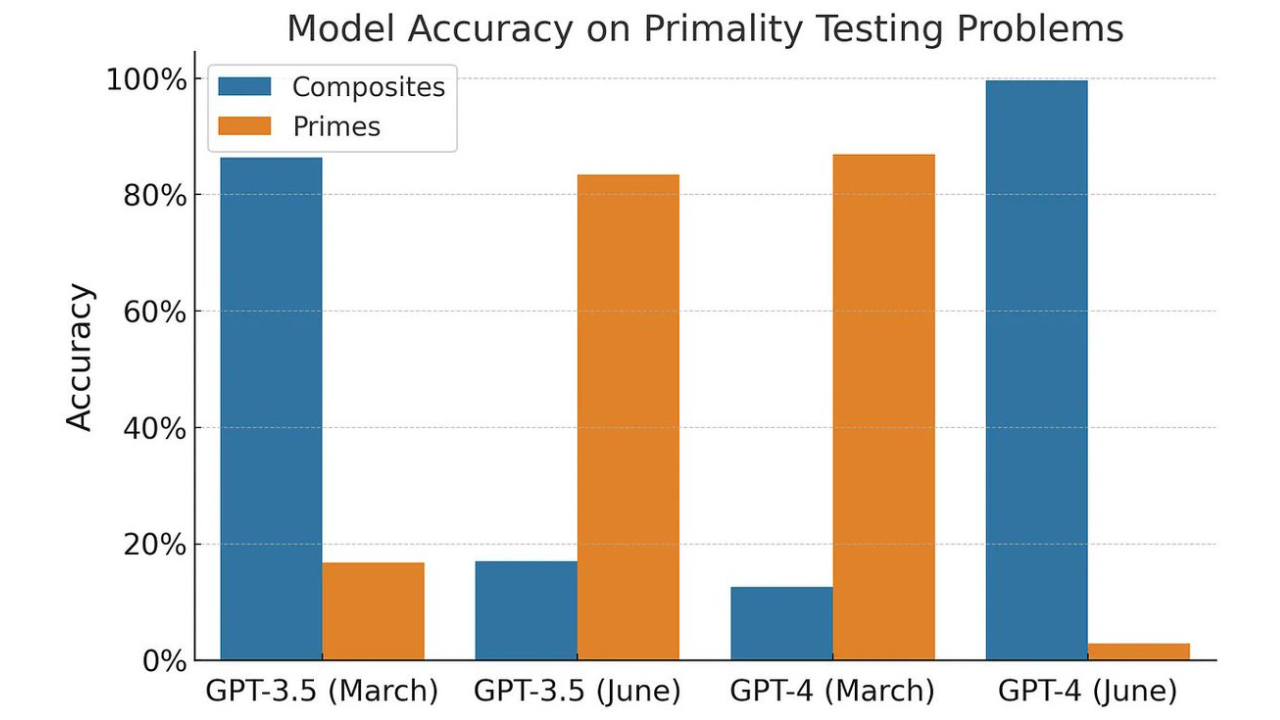
D’autres chercheurs ont reproduit l’étude avec des nombres composites (= non-premiers), et on constate une inversion quasi-parfaite des résultats.
Ici, la conclusion est claire : ChatGPT n’est pas devenu mauvais, il l’a toujours été sur cette tâche !
Je trouve ça vraiment dommage que cette fausse information soit reprise massivement par des journalistes sans esprit critique, et sans consulter de spécialistes.
Une belle leçon à tirer de cette histoire : si vous lisez “selon une étude de [insérer université américaine ici]”, vous avez 99% de chances de lire n’importe quoi.
Ici, il aurait fallu dire “étude sans validation par peer-review, co-écrite par un étudiant de Stanford”. Pas ouf.
J’espère que cet article improvisé vous aidera à vous protéger contre les articles aux airs faussement scientifiques qui racontent n’importe quoi 😉
Et si l’IA vous intéresse, voici un autre article de vulgarisation sur le fonctionnement de DALL·E 2 qui pourrait vous plaire !
Un programme de 15 lignes de code Python arrive à rivaliser avec les mei...
Voici comment j’ai découvert un réseau d’entreprises fictives sur Linked...
J’ai donné 5 exercices de code à ChatGPT et GitHub Copilot, voici les ré...
contact@mathishammel.com
Copier
contact@mathishammel.com

{kind=link}