
Ce programme de 15 lignes rivalise avec les meilleures IA !
Un programme de 15 lignes de code Python arrive à rivaliser avec les mei...
Mini-article pour vous expliquer cette formule magique capable de détecter si un nombre est premier ⤵️ https://twitter.com/fermatslibra…
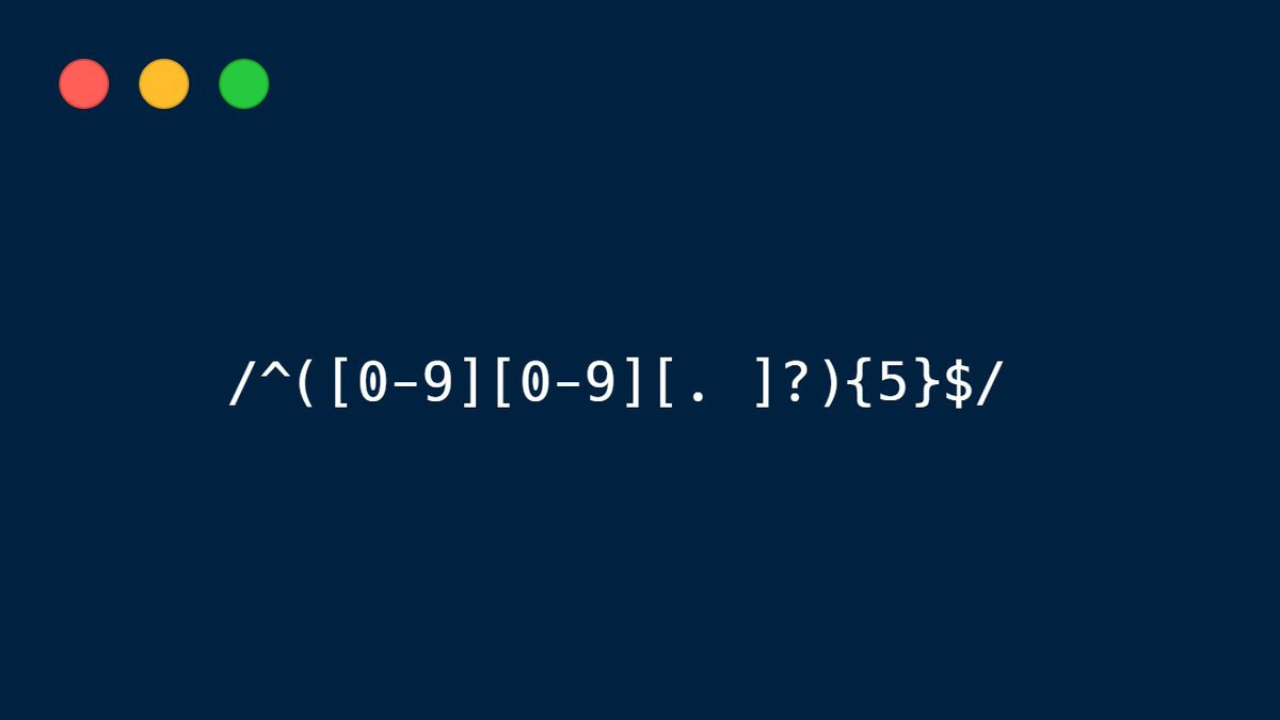
Cette chaîne de caractères assez cryptique est une expression régulière (ou regex).
C’est une manière de décrire des motifs de caractères pour qu’un ordinateur puisse les détecter dans un texte.
Commençons par un exemple plus simple :

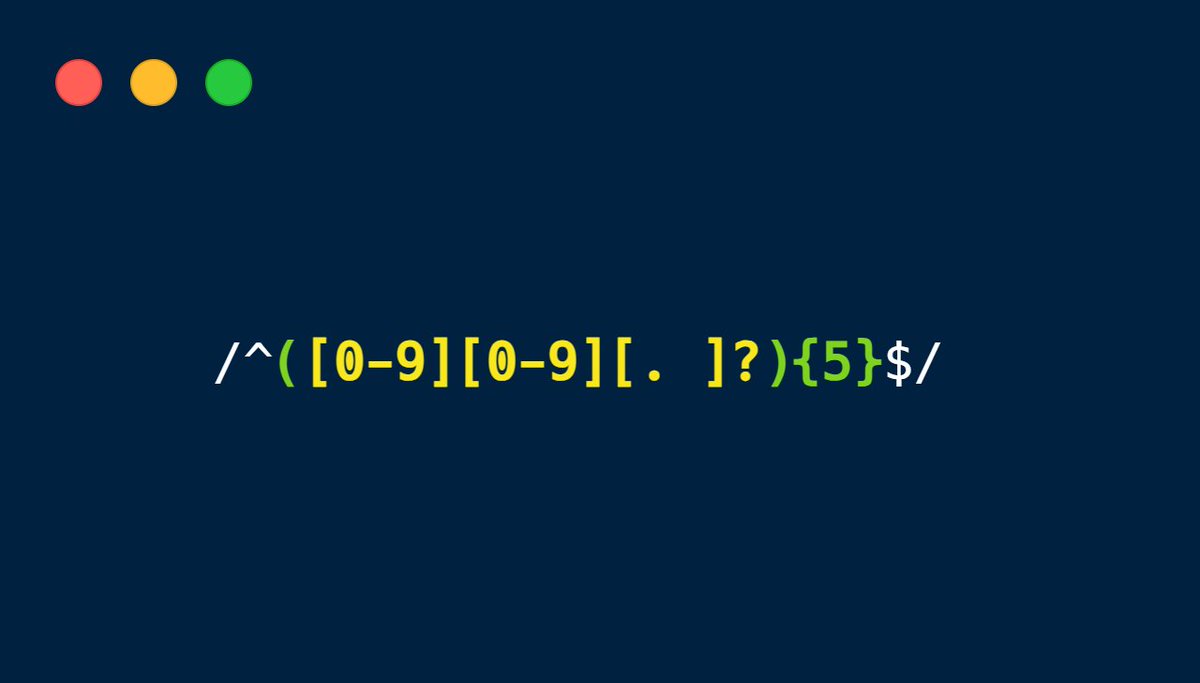
La sous-partie en jaune ci-dessous nous indique qu’il faut chercher un motif de la forme suivante :

En mettant ce groupe entre parenthèses et en ajoutant un {5} à la suite, ça indique qu’on recherche une répétition de ce motif 5 fois d’affilée.
Il nous reste quelques caractères à comprendre :
Le ^ indique que le motif doit commencer au début du texte dans lequel on cherche, et le $ indique qu’il se termine à la fin du texte.
Les slashs sont une manière d’indiquer qu’il s’agit d’une regex.
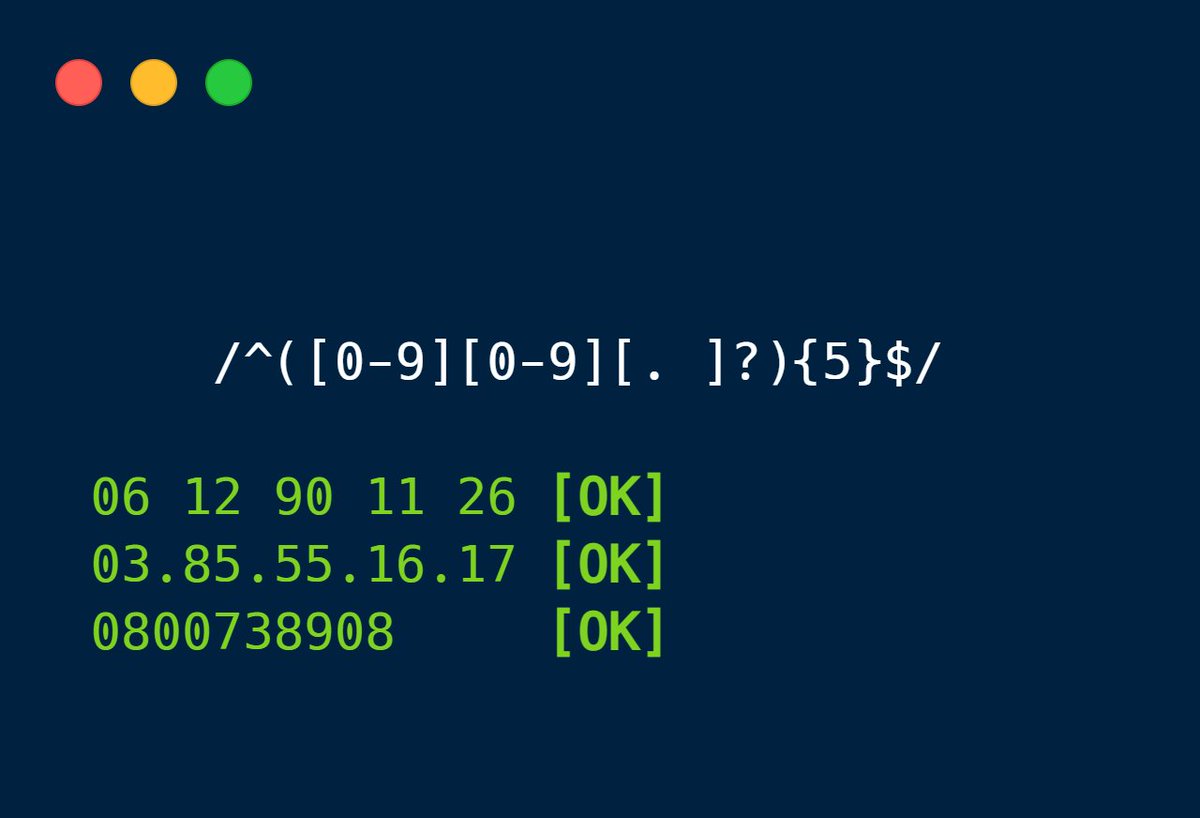
Cette expression régulière va donc nous permettre de vérifier si une chaîne de caractères respecte le format donné, à savoir 5 ensembles de 2 chiffres potentiellement séparés par des espaces et/ou points.
On a donc créé un vérificateur de numéros de téléphone !
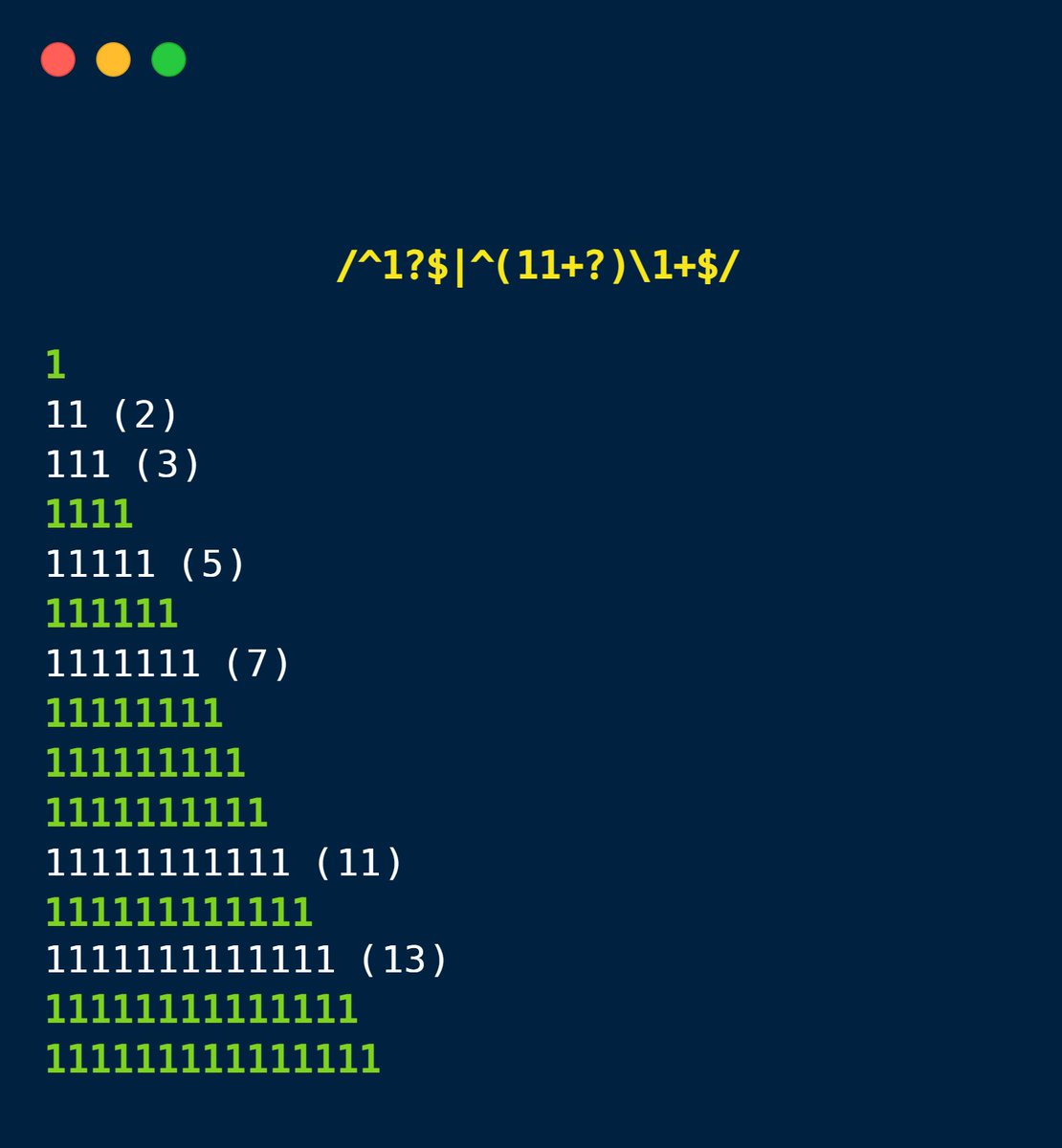
Revenons à la regex capable de détecter des nombres premiers : quel est son fonctionnement ?
Ici encore, on va la découper en sous-parties pour y voir plus clair.

Pour que cette expression fonctionne correctement sur un nombre N, il faut convertir celui-ci en notation unaire, soit N fois le caractère “1”.
Pour savoir si 12 est un nombre premier (spoiler : non), il faudra donc exécuter la regex sur la chaîne 111111111111.

Ici, on a deux motifs séparés par un caractère | qui indique que notre texte doit correspondre à la sous-expression de gauche ou celle de droite.

La sous-expression de gauche est toute simple. On va rechercher le motif suivant dans le texte :
^ : Début du texte1? : Rien ou un caractère 1$ : Fin du texteEn gros, on va matcher uniquement si le texte est une chaîne vide (N=0) ou un seul caractère 1 (N=1).

L’autre moitié de l’expression est moins triviale. On va devoir introduire 2 nouveaux concepts.
Le caractère + indique qu’on cherche au moins une répétition du caractère qui le précède.
La partie ci-dessous indique qu’on cherche un 1 suivi d’au moins un autre 1 (donc 11, 111, 1111, etc.)

On peut ignorer le point d’interrogation qui suit ce motif 11+, c’est une optimisation qui permet d’améliorer la performance de la recherche. (ici, le duo “+?” indique que si plusieurs matchs valides existent, le moteur de regex doit renvoyer le plus petit d’entre eux.)
Pour finir, on a \1+ : au moins une répétition du premier groupe capturé.

Le premier groupe capturé, c’est l’expression entre parenthèses : si la valeur matchée par le motif 11+? était par exemple 1111, alors \1+ devra correspondre à 1111, 11111111, 11111111111, …
Le motif de droite nous indique donc qu’il faut un motif d’au moins 2 caractères “1”, qui se répète au moins 2 fois.

Ce motif correspond à un nombre N qui admet au moins un diviseur autre que 1 et N 😁
Pour conclure, les seuls nombres validés par notre expression régulière sont ceux qui ne sont pas premiers !
J’espère que ce mini-article improvisé vous a plu 😁
Quelques ressources complémentaires :
Un programme de 15 lignes de code Python arrive à rivaliser avec les mei...
Trop beau pour être vrai ? Hier soir, j’ai partagé un compte qui a préd...
Sur le deuxième round du challenge Meta Hacker Cup, je me suis à nouveau...
contact@mathishammel.com
Copier
contact@mathishammel.com


{kind=link}