



404CTF 2024 - Sea side channel
Ce challenge en 4 parties est l'un de ceux qui a été le moins flaggé sur...
Pour résoudre ce challenge de reverse du 404CTF, j’ai utilisé une technique assez redoutable qui est très souvent oubliée par les créateurs de challenges.
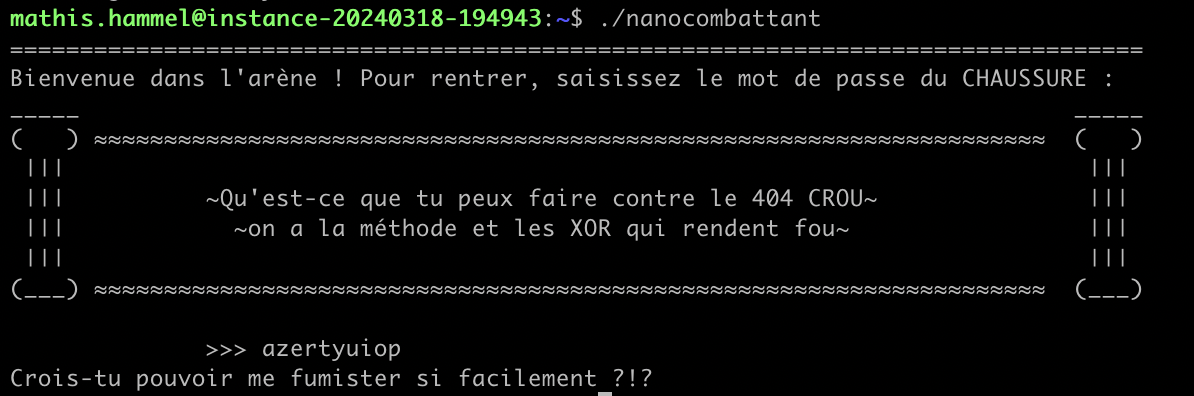
Le chall se présente comme un crackme très standard, on doit trouver le bon mot de passe qui nous affichera le message “Bienvenue dans l’arène” (en vocabulaire cracking, ce message est appelé le goodboy).
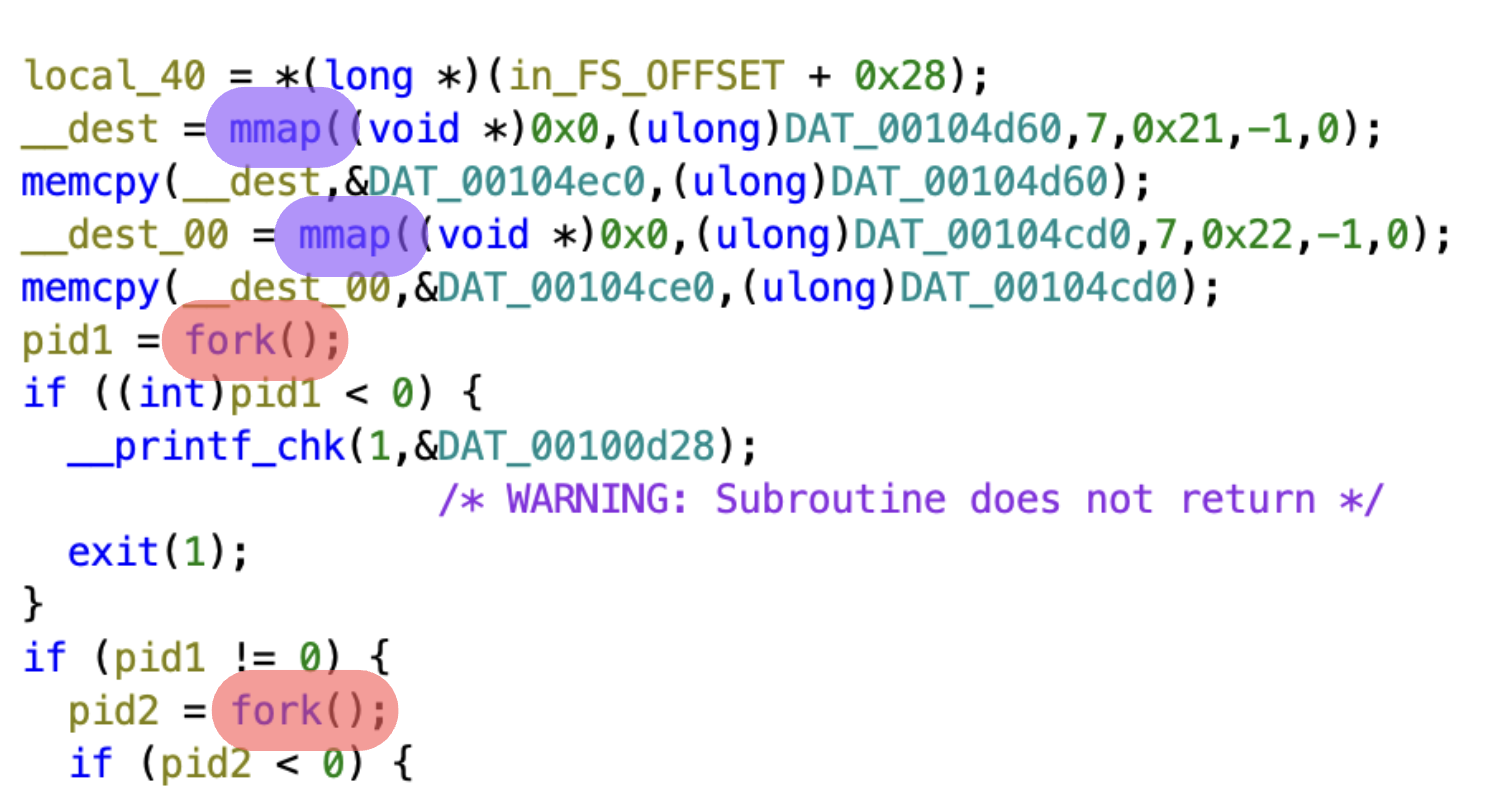
En ouvrant le binaire dans Ghidra, je remarque directement deux calls à la fonction fork, qui est une fonction du noyau permettant de dupliquer le processus en cours (dans le cas général, on s’en sert pour paralléliser des opérations).
Dans les challenges de reverse, le fork est généralement utilisé à d’autres fins :
Dans ce cas, la fonction fork ne semble appelée que 2 fois, ce qui me fait plutôt pencher pour la deuxième option. Cette intuition est renforcée par les appels à mmap, qui vont créer des segments de mémoire partagée (ça permet de mettre en place une communication inter-processus).
On a donc manifestement un processus parent qui délègue certaines parties du calcul à 2 processus enfants.
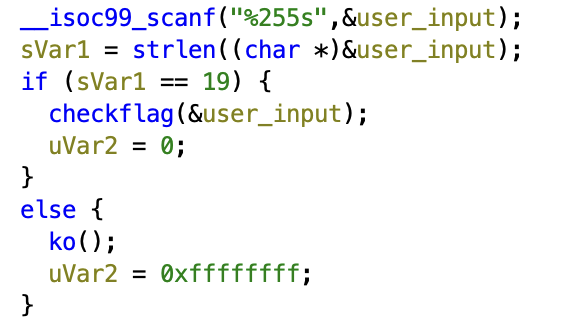
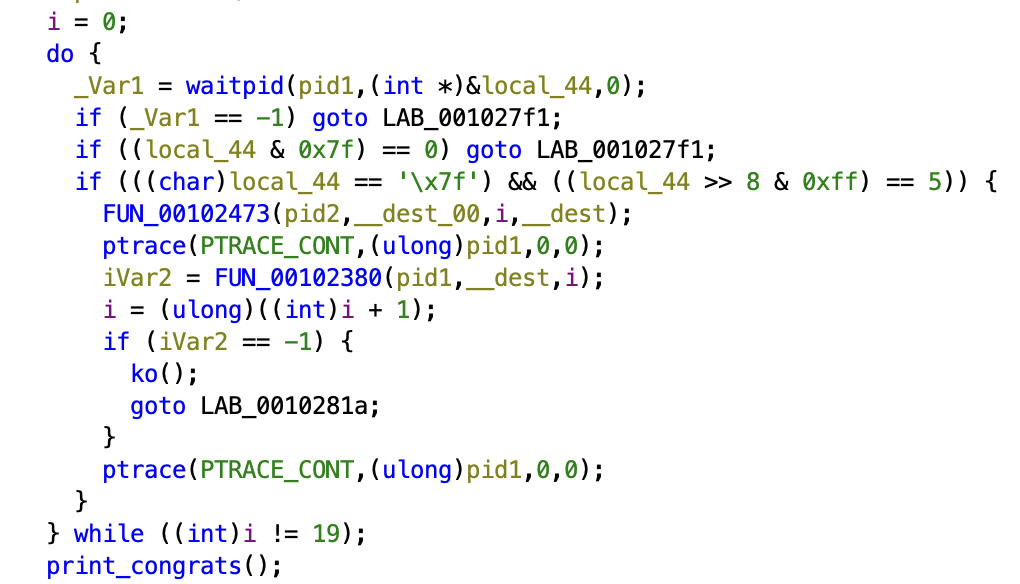
On peut voir que la fonction checkflag est appelée seulement si l’entrée utilisateur fait 19 caractères de long. Dans sa boucle principale, cette fonction effectue 19 itérations donc il est fort probable que chaque caractère soit traité indépendamment. On ne va pas étudier le contenu des fonctions appelées, vous verrez que ce n’est pas nécessaire et qu’on va gagner beaucoup de temps.
De manière intuitive, on peut supposer (à juste titre) que le programme fonctionne à peu près de la manière suivante (ici en Python) :
for i in range(19):
if check_input(user_input[i], i) == -1:
print('Raté :(')
exit()
print('Bravo !')
Dès que le programme rencontre un caractère incorrect, il s’arrête immédiatement sans vérifier les suivants. Et c’est cette porte d’entrée qu’on va pouvoir exploiter pour trouver le mot de passe attendu !
Admettons que l’appel à check_input prenne 1 seconde pour s’exécuter. Si le programme s’exécute en 3 secondes lorsqu’on lui passe l’entrée “azertyuiop123456789”, on peut alors imaginer que check_input a été appelé 3 fois :
Sans aucune connaissance approfondie sur le fonctionnement de check_input, on peut donc déduire que le mot de passe attendu commence par “az”. Si vous faites un peu de crypto, vous aurez reconnu ici une timing attack, une forme très simple de side-channel attack (attaque par canal auxiliaire). Pour découvrir une forme plus complexe de side-channel attack, je vous invite à lire cet autre writeup du même CTF qui utilise la puissance consommée par un processeur pour faire fuiter une clé cryptographique.
Remarquez que cette vulnérabilité pourrait être complètement évitée avec une modification très simple pour forcer l’exécution des 19 itérations, qui nous obligerait à analyser le fonctionnement de check_input :
is_ok = True
for i in range(19):
if check_input(user_input[i], i) == -1:
is_ok = False
if is_ok:
print('Bravo !')
else:
print('Raté :(')
On appelle ça des opérations en temps constant, c’est très utilisé en cryptographie. Heureusement pour nous, le créateur du challenge a oublié de mettre cette protection en place :)
Dans notre exemple simplifié où chaque itération demande 1 seconde de calcul, le temps d’exécution sera effectivement une cible de choix pour la side-channel attack. Mais pour notre crackme, une itération sera plutôt de l’ordre de la milliseconde, on aura du mal à distinguer cette faible variation parmi tous les autres facteurs du système pouvant influencer le temps d’exécution.
Heureusement, il existe d’autres manières de mesurer avec une grande précision le nombre d’itérations effectuées par le programme. J’ai ici choisi d’utiliser strace pour compter les appels système, mais je pense que les deux autres méthodes que j’utilisent souvent sont importantes dans d’autres cas et méritent d’être mentionnées :
Le nombre d’instructions exécutées sur le processeur par un programme donné se mesure plutôt bien sur les puces Intel, grâce à l’outil Pin (qui peut néanmoins être infernal à installer et utiliser).
Voici un exemple d’analyse de Pin sur l’exécution de la commande cat fichier.txt, qui nous indique ici que la commande a exécuté 243464 instructions assembleur :

Cette méthode revient globalement à mesurer le temps d’exécution, mais de manière beaucoup plus précise car ses mesures ne fluctuent (quasiment) pas d’une exécution à l’autre.
Je n’ai pas utilisé pin pour ce challenge car il avait tendance à crash aléatoirement sur mon système et j’avais la flemme d’implémenter la gestion d’erreurs.
De très nombreux programmes sont compilés avec un linking dynamique, c’est à dire qu’ils n’ont pas besoin d’embarquer le code de certaines fonctions standard (printf, rand, malloc, etc.) en supposant que celles-ci seront déjà présentes sur le système qui les exécute.
Ces appels de fonctions dynamiques sont assez faciles à tracer, et on peut utiliser pour ça la commande ltrace qui permet de logger chaque appel dynamique ainsi que ses paramètres.
Pour illustrer ltrace, voici un exemple de trace sur l’appel à cat fichier.txt :
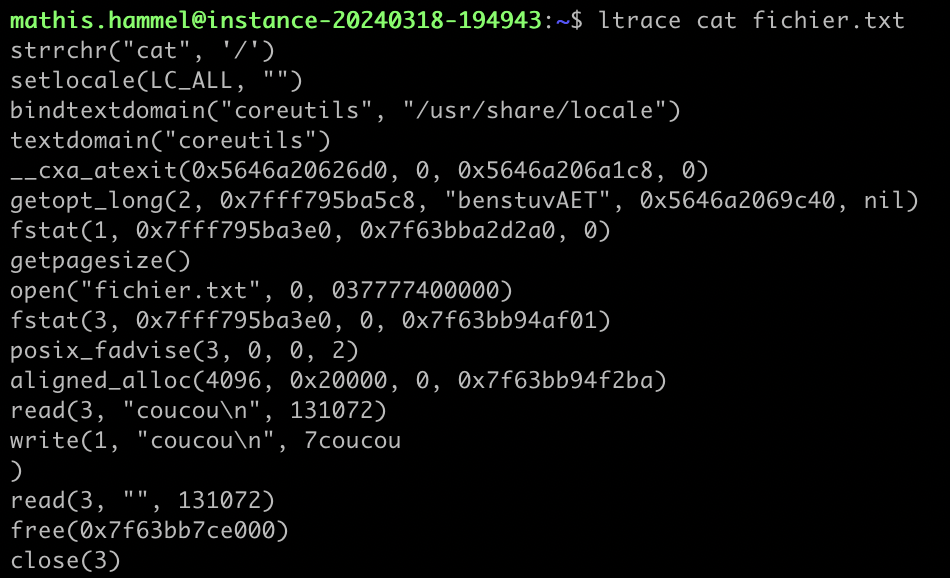
Malheureusement, cette méthode n’était pas utilisable directement car l’outil se comporte comme un debugger et se faisait directement détecter par la protection anti-debug du challenge. Je pense qu’il aurait été relativement simple de patcher le binaire pour contourner cette difficulté, mais la solution ci-dessous permettait de s’économiser ce travail.
La commande ltrace est aussi très utile en reverse pour comprendre le fonctionnement général d’un binaire sans avoir à le décompiler en entier ni l’exécuter dans gdb, et on peut même parfois voir des flags passer en clair dans des appels à strcmp 😉
Pour fonctionner correctement, tous les programmes ont besoin de communiquer avec le kernel pour effectuer diverses actions : lire/écrire dans la console ou des fichiers, ouvrir une connexion réseau, etc.
Ces communications avec le noyau se font via des appels système, qui peuvent facilement être interceptés et affichés. Dans le cas du challenge Nanocombattants, chaque itération génère de nombreux appels système, qui servent notamment à la communication et à la synchronisation entre les 3 processus. Voici un exemple d’exécution de strace sur le challenge :
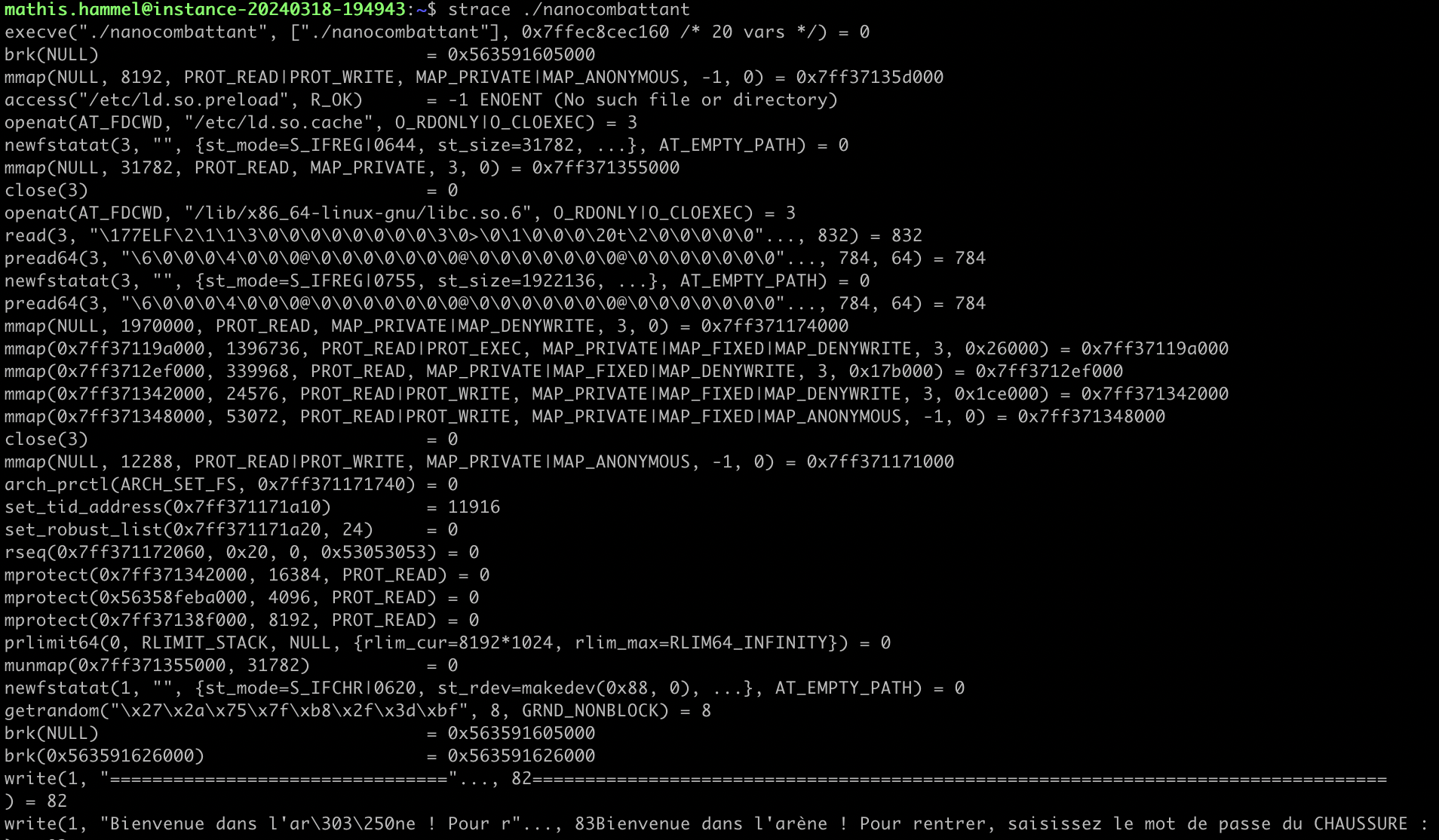
Ici, on assiste à l’initialisation de l’exécutable (je ne saurais pas expliquer la signification du quart de ces lignes), et on voit en bas de la capture l’affichage du message de bienvenue sur le challenge.
En regardant tout simplement la taille de l’output généré par strace, on va pouvoir deviner le nombre d’itérations effectué, et donc on peut bruteforcer chaque caractère en commençant par le premier :
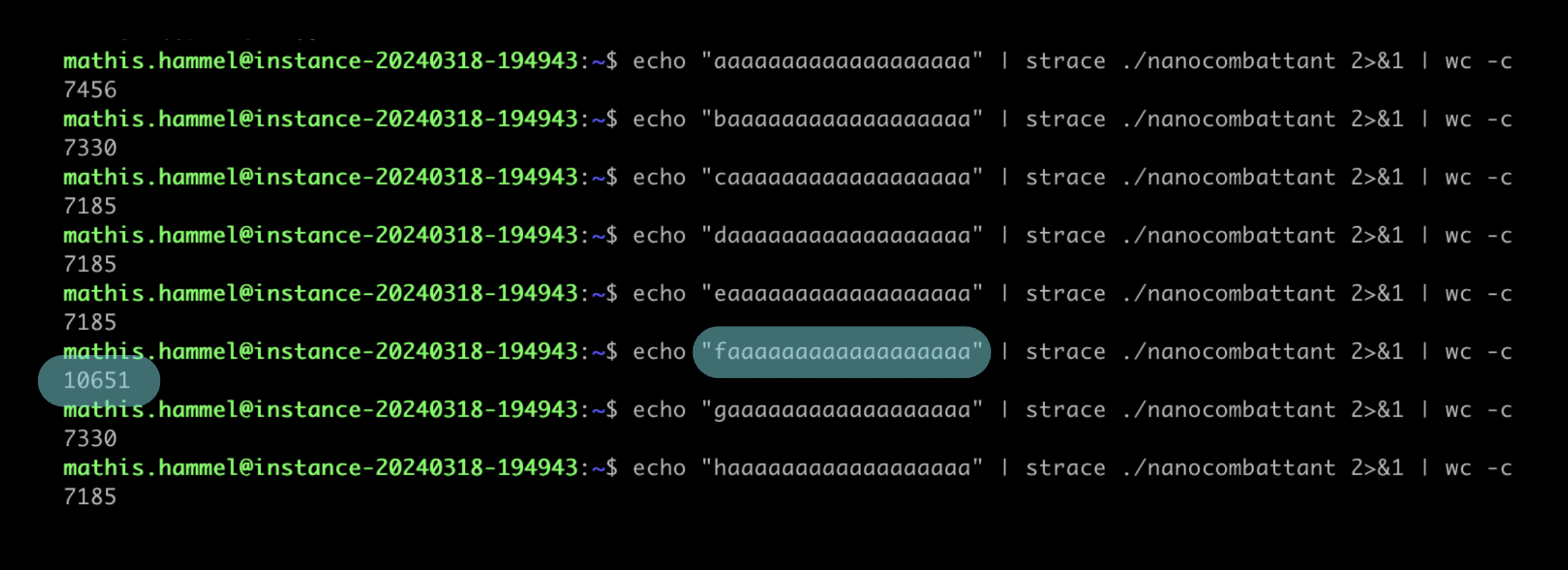
On remarque que la sortie de strace contient généralement entre 7100 et 7500 caractères, sauf quand le premier caractère du mot de passe entré est un “f”, ce qui provoque un pic très net à 10651 caractères. On peut donc en déduire que ce caractère est correct à cette place. Il suffit de procéder à la même opération pour les 18 caractères suivants et on récupère le flag sans difficulté ☺️
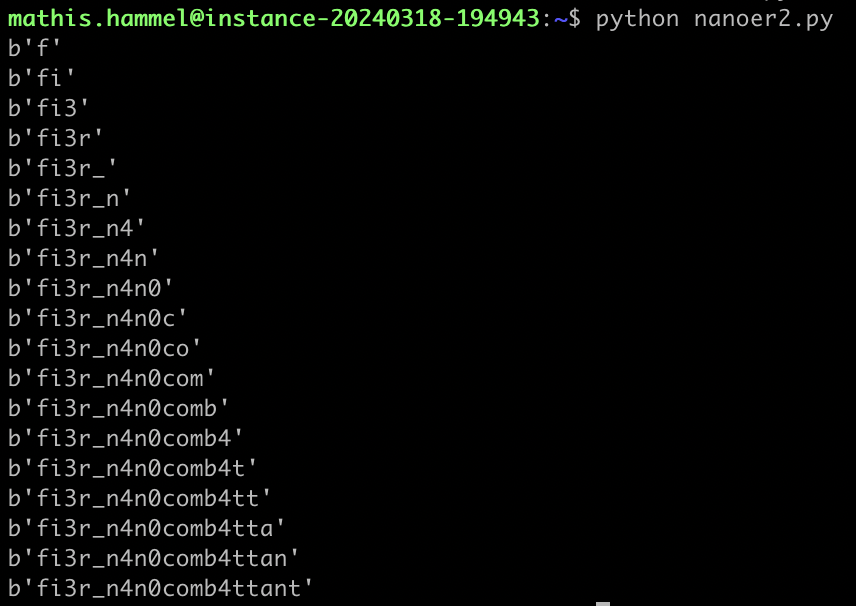
J’étais moyennement partant pour exécuter 2000 fois la même commande à la main pour bruteforcer chaque caractère du mot de passe, donc j’ai mis en place un petit bout de code Python pour l’automatiser :
from subprocess import Popen, PIPE
def run_nano(s):
p = Popen(['strace', './nanocombattant'], stdin=PIPE, stdout=PIPE, stderr=PIPE)
_, out = p.communicate(s + b'\n')
return len(out)
flag = b''
for pos in range(19):
scores = []
for b in range(32, 127):
s = flag + bytes([b])*(19-pos)
scores.append((run_nano(s), b))
flag += bytes([max(scores)[1]])
print(flag)
Moins de 30 secondes plus tard, le mot de passe apparaît et permet de flag 950 points presque gratuitement, en ayant à peine regardé le contenu de l’exécutable !
Je publierai certainement d’autres writeups de reverse et crypto cette semaine; n’hésitez pas à utiliser le formulaire de contact ci-dessous si vous avez une demande de writeup sur un challenge en particulier !
Ce challenge en 4 parties est l'un de ceux qui a été le moins flaggé sur...
L’été dernier, Elon Musk a annoncé que certains comptes Twitter Blue pou...
Bon. J’ai pris la difficile décision de quitter mon travail chez CodinGa...
contact@mathishammel.com
Copier
contact@mathishammel.com

{kind=link}