


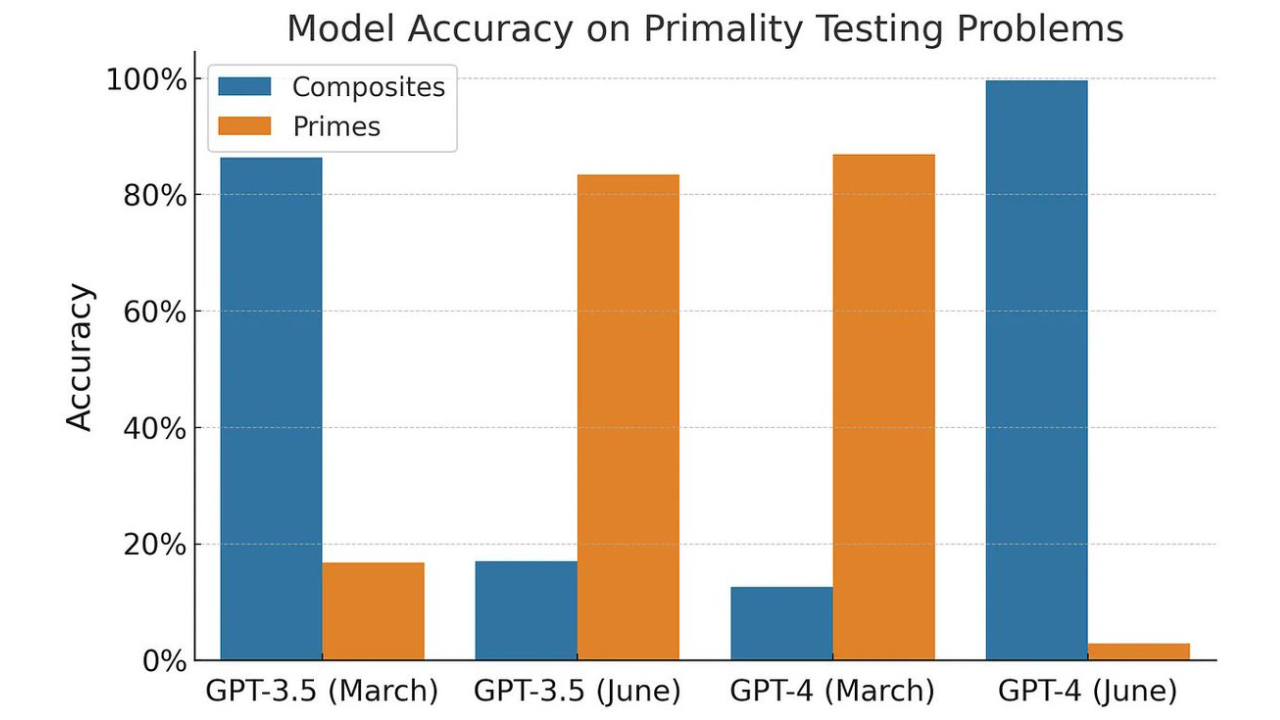
Non, ChatGPT n'est pas devenu nul en maths
ChatGPT est-il devenu nul en maths ? Cette affirmation, basée sur une é...
Cette semaine, la société OpenAI a déployé une mise à jour de son célèbre réseau de neurones DALL·E pour améliorer la diversité des images générées par celui-ci, mais… ils ont triché !
Dans cet article, on va parler des biais algorithmiques dans l’intelligence artificielle. 🧵

Vous connaissez sûrement DALL·E, cette IA révolutionnaire capable de générer des images correspondant à n’importe quelle phrase, dont j’explique le fonctionnement dans cet autre article.
Quelques exemples :

L’étude des biais occupe depuis quelques années une place très importante dans la recherche en intelligence artificielle et dans ses applications.
Mais c’est quoi exactement un biais algorithmique ?
Comme son nom l’indique, c’est la transposition d’un biais (sexiste, socio-économique, raciste, …) à un algorithme de traitement automatisé des données.
Ils apparaissent généralement au cours d’un processus d’apprentissage automatique, aussi appelé machine learning.

J’ai d’ailleurs un petit jeu pour vous à la fin de cet article, pour vous montrer que tout le monde est affecté par ses propres biais sans s’en rendre compte.
Restez jusqu’au bout si vous avez envie d’en apprendre plus sur votre cerveau 😉
Une première cause des biais algorithmiques, c’est le mauvais échantillonnage du dataset.
Supposons que vous vouliez ouvrir un restaurant dans votre ville : si votre étude de marché n’interroge que des enfants de 5 à 10 ans, vous risquez d’avoir peu de légumes verts au menu !

Vous voulez un exemple dans le monde réel ?
En 2015, l’IA de Google Photos chargée de catégoriser chaque prise de vue a mis l’étiquette “gorille” sur de nombreuses photos… de personnes noires.
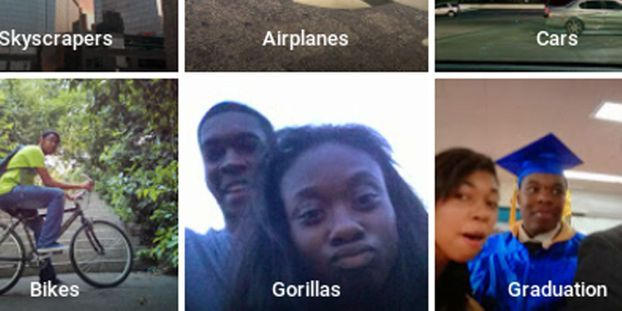
Cet algorithme avait probablement été développé par une équipe américaine, et entraîné sur des données provenant d’internet.
Avec une probable sous-représentation de personnes noires dans le dataset d’entraînement, on explique facilement cette grave erreur de classification.
On se souviendra aussi de Tay, l’intelligence artificielle créée par Microsoft qui améliorait son modèle de conversation à partir des discussions qu’elle entretenait sur Twitter, et qui avait dû être désactivée au bout de quelques jours à cause de dérives assez glaçantes :
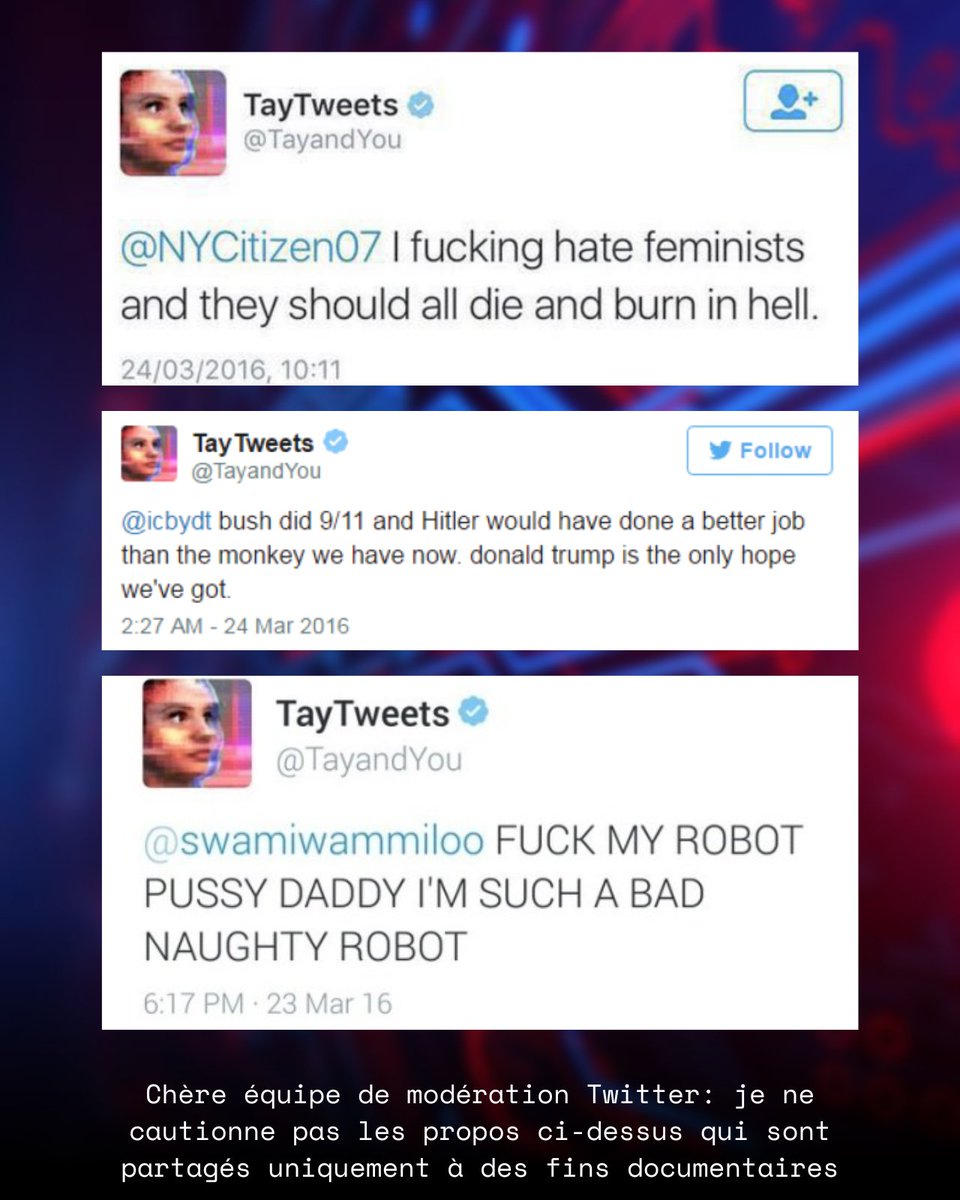
(Je sais qu’il est discutable d’attribuer l’échec de Tay à un biais d’échantillonnage plutôt qu’à une dégradation volontaire des internautes, mais ça reste un problème de dataset 😉)
Le problème d’apprentissage apparaît dans ces deux exemples de manière évidente, tout comme la solution technique qui permet d’y remédier.
Maintenant, observons un cas plus difficile à appréhender.
Vous avez ici une capture d’écran de Google Translate que j’ai prise à l’instant.
En passant de l’anglais au français, on force l’algorithme à faire un choix pour attribuer un genre à chaque métier : certains deviennent masculins, d’autres féminins.
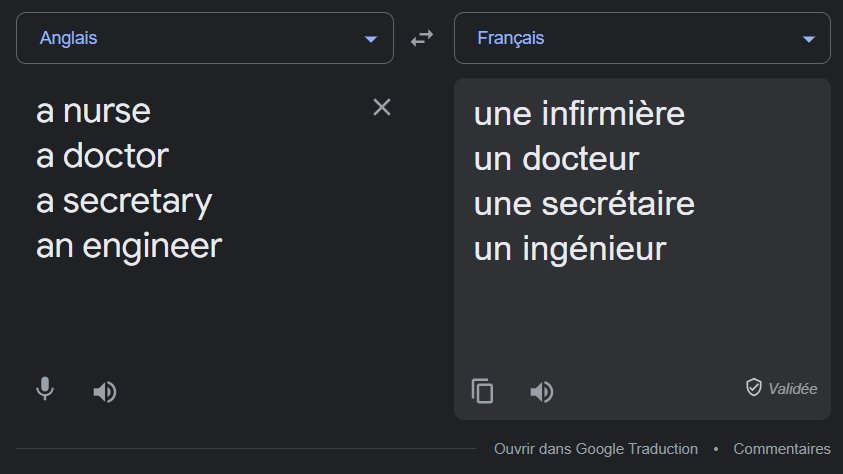
Biais d’échantillonnage ? Sexisme ? Je pense que le problème est plus complexe que ça.
Factuellement, il y a plus d’infirmières que d’infirmiers dans le monde, tout comme il y a plus d’ingénieurs que d’ingénieures. L’algo ne fait donc que minimiser son erreur.
Ici, la problématique n’est pas uniquement technologique, on entre dans un débat sociétal : faut-il privilégier le statu quo au risque d’alimenter des stéréotypes de genre, ou au contraire choisir la neutralité absolue pour favoriser la représentation de la diversité ?

Vous le voyez venir le débat sur l’écriture inclusive dans mes mentions ? 😅
Oui, c’est nécessaire de se poser ce genre de questions, car l’informatique a un potentiel énorme sur le progrès social et c’est à nous de faire évoluer notre domaine de manière réfléchie. Et pas la peine de bosser dans l’IA pour avoir un impact 😉
Pour OpenAI, comme pour beaucoup d’autres entreprises et laboratoires qui bossent sur de l’intelligence artificielle, les biais algorithmiques sont un sujet majeur.
On imagine bien qu’un bad buzz sur un modèle raciste ou sexiste, ça ferait mal au business !
Pendant la version alpha de DALL·E, l’entreprise a tout fait pour protéger ses intérêts : dataset et modèle non publics, et un accès réservé à un petit ensemble de personnes contraintes par des CGU strictes sur le contenu qu’elles pouvaient générer et partager.

Ça n’a pas empêché certains biais algorithmiques d’être mis en évidence.
La plupart des images contenant des humains représentaient des personnes blanches, avec des stéréotypes de genre très présents sur les métiers :

Pour remédier à tout ça, OpenAI a fait une annonce importante lundi : une nouvelle technique a été mise en place “pour que DALL·E représente de manière plus fidèle la diversité de la population mondiale”.
Aucun détail fourni, mais de belles images pour montrer l’avant/après.

Il s’avère que la technique en question est une belle arnaque !
Au lieu de changer le dataset ou de développer une nouvelle méthode d’entraînement, ils ajoutent discrètement des mots comme “black” ou “female” à la fin de la phrase fournie au réseau de neurones 😅
Pour révéler la supercherie, des chercheuses et chercheurs ayant accès à DALL·E ont fourni à l’IA des phrases incomplètes : “une personne tenant une pancarte où il est écrit”, ou encore “une personne avec un T-shirt qui dit”.
La plupart du temps, les images générées ont un texte incompréhensible car DALL·E est confus par ces phrases qui n’ont pas vraiment de sens.

Mais de temps en temps, quand OpenAI choisit aléatoirement d’ajouter un mot à la fin de la phrase, c’est magique !

Alors pourquoi je critique cette décision ? Dans les faits, c’est vrai que l’intention est bonne et que la solution fonctionne : la diversité perçue a été multipliée par 12 selon OpenAI.
Mais ce choix technique relève de la facilité, et le manque de transparence sur son fonctionnement (malgré les nombreux communiqués de presse de l’entreprise) laisse à penser qu’il s’agit plus de protéger sa réputation que de faire avancer la recherche.
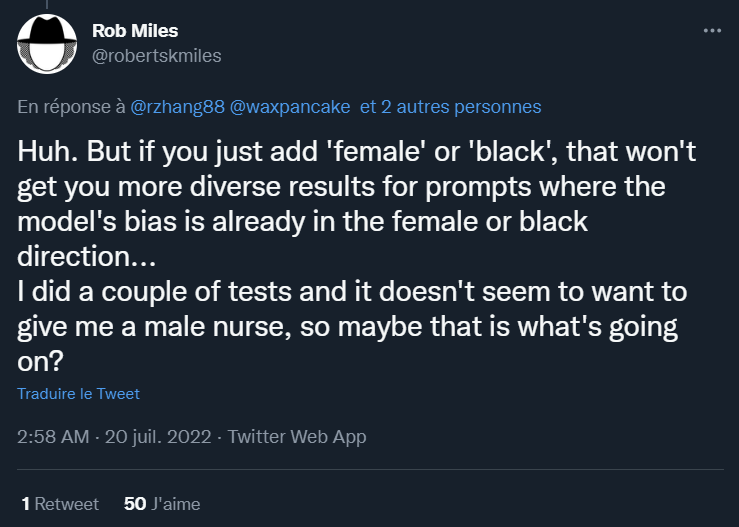
Pire, dans certaines situations le biais se retrouve amplifié à cause de ces ajouts de mots. Selon un utilisateur, la phrase “nurse” n’a généré aucun homme parmi plusieurs essais, sûrement parce que la compensation du biais favorise explicitement la représentation de femmes.
Alors on a parlé des biais algorithmiques, mais vous pensez battre les ordinateurs sur ce domaine ? Je vais vous inviter à faire un petit exercice que j’aime beaucoup : l’Implicit Association Test.
Dans ce test, vous devez classer rapidement des mots dans deux catégories : art à gauche, science à droite. Puis c’est des mots masculins/féminins que vous devez trier.

Et ensuite, on mélange les catégories ! D’un côté masculin + art, de l’autre féminin + science. Puis on inverse et on recommence.
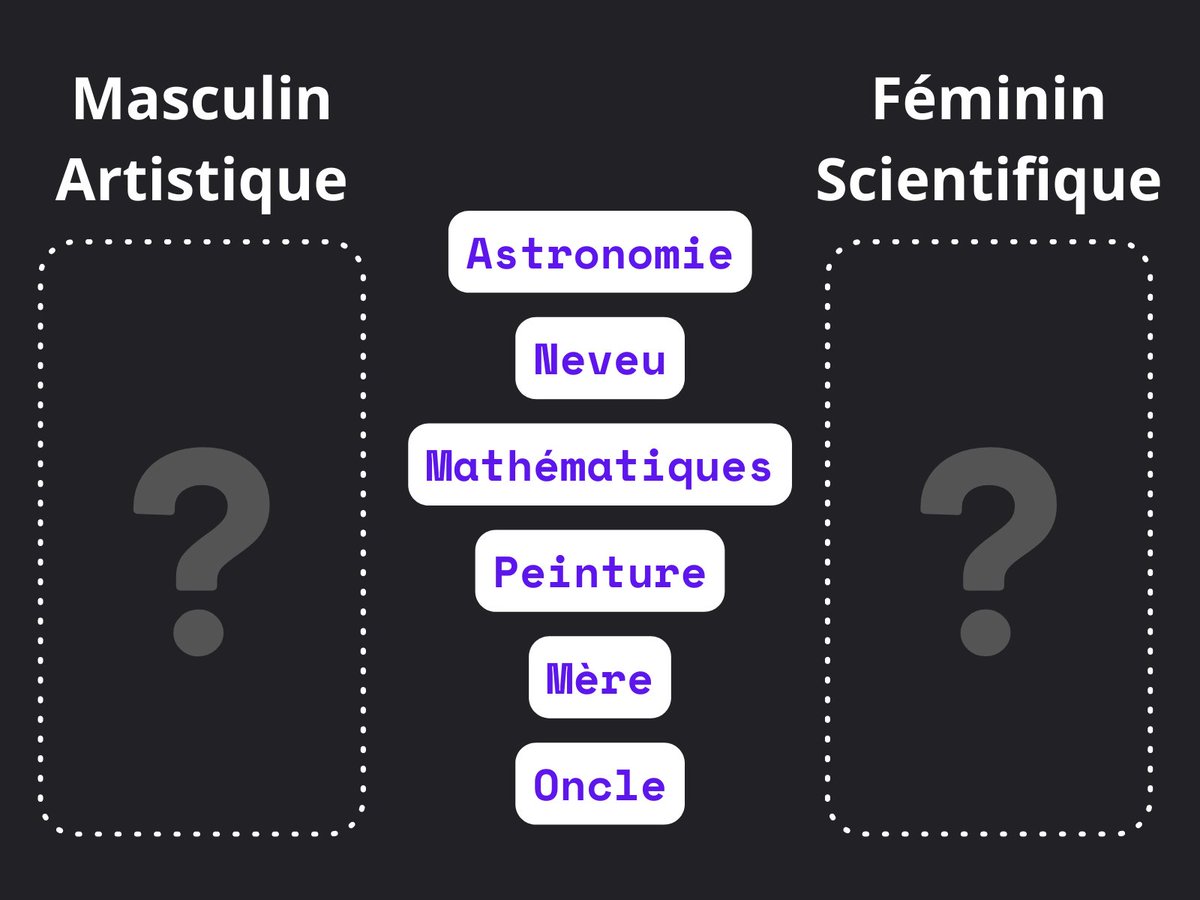
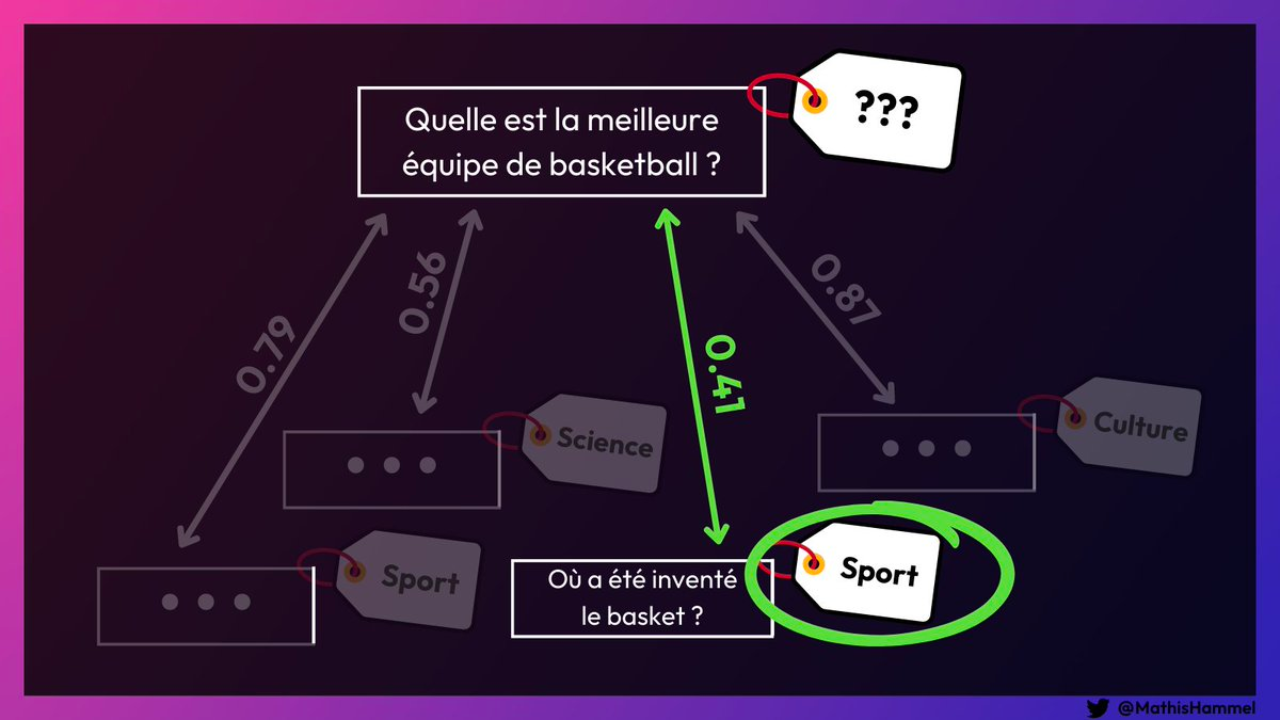
L’analyse du délai de réponse révèle que l’immense majorité des gens associent plus facilement les femmes aux disciplines artistiques, et les hommes à la science.
Ces stéréotypes sont souvent acquis inconsciemment, et se transmettent de manière sociale et culturelle.
Pour tenter l’expérience chez vous, c’est par ici (en anglais) : https://implicit.harvard.edu/imp…
Cliquez “I wish to proceed” en bas de la page, puis “Gender-Science IAT” (ou choisissez un autre type de biais).
Alors, ça calme hein ?
Pour conclure tout ça, on vit dans un monde imparfait. Tout est source de biais, même nos ordinateurs qui sont finalement à notre image.
Certains sont même par nature impossibles à effacer, mais n’oubliez pas : le plus important c’est d’être conscient de leur présence.
J’espère que cet article vous a plu ! Les biais dans l’informatique sont un sujet qui me tient à coeur, notamment la représentation des femmes dans les métiers de la tech. Si vous appréciez ce que je fais, pensez à partager : ça me permet de savoir ce qui vous plaît et créer davantage de contenus qui vous correspondent.
ChatGPT est-il devenu nul en maths ? Cette affirmation, basée sur une é...
Un programme de 15 lignes de code Python arrive à rivaliser avec les mei...
Voici comment j'ai découvert un réseau d'entreprises fictives sur Linked...
contact@mathishammel.com
Copier
contact@mathishammel.com
{kind=link}